


Sometimes take your hands off from your system but it should still continue to operate like a pilot driving an airplane
Remember the day when Facebook, WhatsApp, and Instagram were down for hours? — It could have shaken a lot of people but not some. One who knows failure is inevitable in software systems, one who has experienced it, one who knows their system limits, one who is anticipating it, they know what’s coming.
Software systems that we build can end up as victims of many types of failures. Network failure, coding failure, service failure, database failure, memory failure, resource failure, cloud service provider failure, and much more. Availability of a system is easily compromised on various occasions and one needs to be prepared about the alternatives on how to service your users in such situations. A service which is down for an hour can impact millions of businesses, people and how they use your system . As a software engineer, it’s their prime responsibility to think about how and when their systems fail even before building it. They should devise a mechanism to fail safely and gracefully, more importantly to stop cascading failures.
I’ll be writing a series of articles on giving red alerts 🔴 on where your systems could fail and how you can design your system so that it gets a green signal 🟢 by recovering or even being resilient to failures by tolerating faults and staying highly available thereafter.
Note: This is neither a deep dive into internals & details of any systems or concepts nor on a DevOps perspective. I’ll be focusing on bringing out the potential chance of system failures in terms of availability especially when building distributed systems like microservices, how you can avoid it when designing your system and developing it, and if occurred how to be alerted to take necessary actions.
1. Fault and failure
In the first place, it’s quite important to understand what is a fault and a failure. A fault is anything which can go wrong in one component or unit of the whole system . A thing which is expected to work in a certain way but found faulty or defective. On the other hand, failure is when the whole system falls short of serving the purpose and what it’s supposed to do . Even the system can be completely down sometimes. Failed to handle user requests, failed to restrict non-authorized access, failed to cope up with system load etc.
Rattling mudguard is a fault; Your bike not starting is a failure
Zero-fault system is literally impossible to design. But we can design it in such a way that faults are tolerated so that it doesn’t become a big threat to cause failures and chaos. Such systems are deemed as fault-tolerant. To make your system highly available, fault tolerance should be at a respectable level and should continue to serve your users even if other parts of your system have failed miserably.
It’s not a battleground where you can battle it out when failure is happening. Either prepare earlier or be tolerant and recover from it.
2. Use case
Let’s take a simple use case of system designing and implementing an ordering platform where the user can order products. I’ve kept the design simple and skipped some architectural components for the sake of focusing on failure scenarios.

User flow
- User sends an order request for a product to the Order service.
- Order service checks with inventory service whether the stock is really available at the time of ordering.
- If no stock is available, it responds back to the user immediately about the unavailability. If available, order service proceeds with payment and connects with external service which takes care of processing the payment.
- Based on the payment service response, the order service stores the state of the order in its own DB e.g. order successful, order failed due to payment, etc.
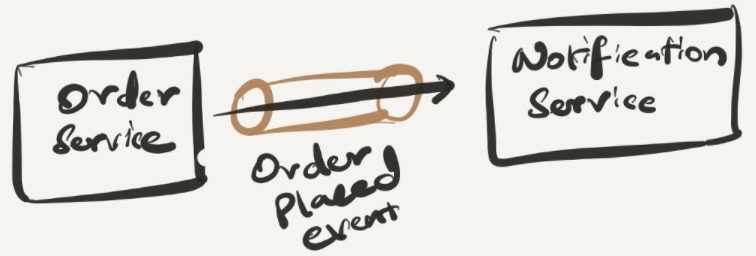
- Send back the response to the user about the order confirmation and send notification to the user for order confirmation in async.
Failure possibilities 🔴
When architecting a system, we should be focusing on potential failures where the system could fail and how we can make it fault tolerant and resilient. Let’s put out some failure possibilities in the system that we’re designing and in the component that’s involved.
Let’s remember whichever that stops our users from ordering an available product is considered as a failure. Below are some failure possibilities:
- If some of these services are down
- If DB is down or too slow
- Service APIs are too slow and timing out
Note: If the notification service is down, it will always send the notification at later stages whenever it’s back up (since async queue is being used). So this is not a real failure as users will still be able to order the product already.
Failure handling 🟢
If the Order service is down
Order service is the core for ordering products on our platform. If that’s down, that’s the end of the road for users. There’s no point for users to use our application. We have to make sure Order service is up as much as possible, best case 24x7. But most of the time it’s not possible to achieve due to facing downtime for various reasons. 3 9’s availability is quite decent and I would recommend any service to have that as a SLA. Having a load balancer in front and multiple instances of the service behind will sustain some failure even if one instance goes down. Goal is to eliminate a single point of failure but one would argue Load balancer becomes that single point of failure now. That’s true but sometimes it’s difficult to tackle it all the way down.
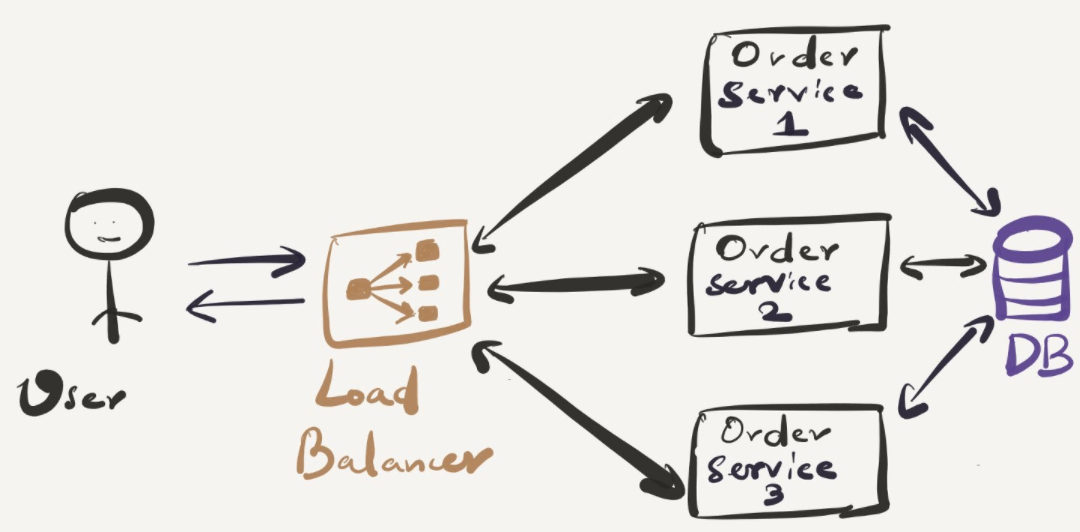
Memory and CPU consumption of the service itself is quite a crucial factor which can bring down the service if not handled with care. Infinite loop with heavy logic, Usage of incorrect data structure etc. can cause adverse effects to your system if not addressed.
If the database is down
Database doesn’t need a special mention when it comes to a single point of failure . If it is down, you can’t serve data to your users unless you have a cache or an alternative datasource. It’s highly unlikely to continue with such a strategy for a long time. Sooner than later one has to bring their DB up and running again. When one designs DB tables, writes queries, performs CRUD operations, it has to be kept in mind that DB is a crucial resource and can halt the whole system anytime if not done right.
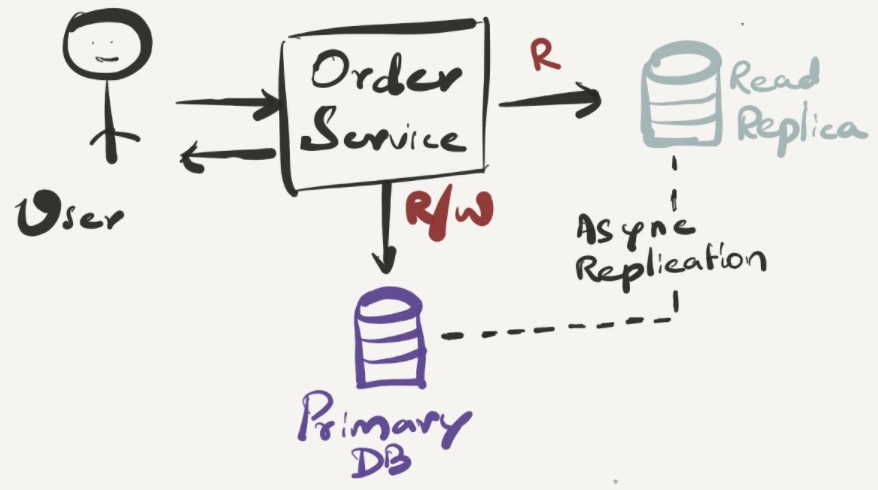
Treating read and write operations separately and having the right strategies like read replica, cache, optimized queries, materialized reads etc. will save some resources for DB and it will continue to serve user’s traffic smoothly.
If the inventory service is down
Inventory service holds the stock details of every product in the system. Before an order gets successfully placed, inventory needs to be checked and updated after the successful order. If the product is not in stock, an error message has to be returned back to the user about the unavailability.
What if the inventory service is down or slow? Should it impact the order placement? Well, if this failure is not taken into consideration, obviously ordering products will fail miserably. In modern days, users can’t wait more than a second to use any sort of software. If we make synchronous call to inventory service from order service and if it’s slow or down, either the API call will timeout or return back an error to the user that order can’t be placed due to internal issues.
If the service itself is not down but it’s DB, cache of inventory details can be managed in inventory service and can be returned to the order service . But this is not as easy as that. All the inventory updates can’t happen in the cache as it’s not suitable for handling transaction heavy operations. But let’s keep that as one solution and see how it works out further. When the primary DB is back again, data from the cache has to be synced with DB for consistency . Increasing complications! — I will not go further into details as this is for another day.
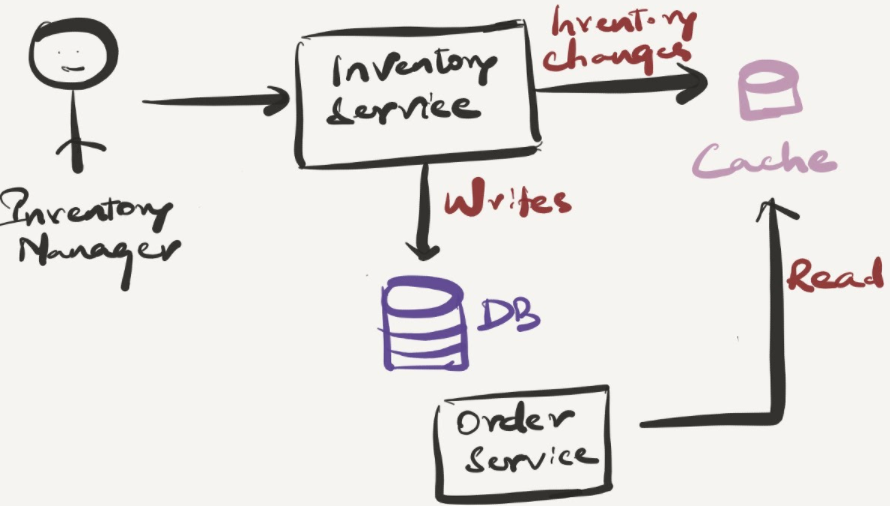
Can we publish inventory details of a product whenever it gets updated and order service subscribes to it so that it can process order even without inventory service intervention? A bit complicated to be frank. Think about this case: whenever the order is placed, inventory has to be reduced by the number of items purchased. Since we’re maintaining the inventory details in order service, we can update it. But the data in the primary inventory service will be outdated now. Even if we decided to update primary data in inventory service, since the service is already down, it couldn’t update the stock immediately as well. So there’s inconsistency all around. Especially with systems like ordering products based on inventory, consistency is quite important.
Taking some measures like previous sections can work but with a system which can’t compromise on consistency and availability as well, it’s quite difficult to find a balance if some failures happen. It’s recommended to keep the system continuing to run by providing the resources more power, choosing the right persistent technologies and having timely monitoring when the service gets degraded.
If the payment service is down or slow
From a system perspective, there could be temporary failures that can occur with payment processing. Since it’s an external system who is processing the payment for us, it could be slow as well. We can have retry logic that retries payment for next 3 times if it continues to fail. If it’s successful, great. If it fails again, retrying should be stopped to not to overload systems and also not to let the users wait for a long time until we retry and get succeeded after ’n’ number of times.
Slowness is deadlier than failure.
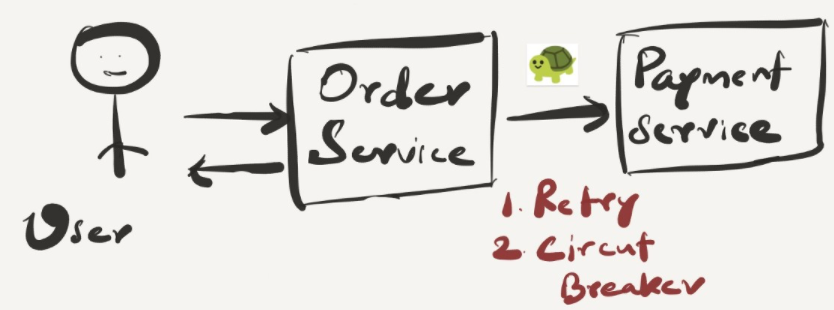
If the payment service is completely unavailable, unfortunately it’s out of your system’s control. We have to fail gracefully and let the user know that payment service is not fast and ask them to try again after sometime. Most importantly we have to execute some compensation transactions to reverse the order and inventory details.
If the notification service is down or slow
If the notification service is down or slow, just the notification will be sent as soon as it is up and running fast. Since this happens as asynchronous communication over a queue, there’s no direct dependency with the API response to the user. Notification service can send the notification anytime.
Reminder to CAP Theorem
With distributed system’s resilience and fault tolerance, it’s quite important to understand CAP Theorem.
C — Consistency, A — Availability and P — Partition tolerance.
What it states is, you can’t have all 3 characteristics at the same time. With distributed systems, since partition is natural between services, you can either choose CP or AP. With the ordering service that we’re building, there’s a high chance that we’re on the side of consistency. But that will hit the availability. So it’s important that we split and maintain separate data sources to serve the need of high availability and consistency. Latency plays a major role in declaring a system fault tolerant. Latency should remain as low as possible to say the system is highly fault tolerant as it continues to serve the users even if there’s a failure and thus maintaining low latency all the way through.
3. Monitoring
Setting up automated monitoring and observability for your systems and their resource consumption would greatly help in stopping your system from going down. With monitoring alerts, you can quickly act upon the faults so that it doesn’t blow up big to cause downtime to your system. It’s a fault prevention mechanism more or less.
You can’t improve things that you can’t measure.
I’ll be covering monitoring for failures in a separate article as it’s a topic of its own.
4. Conclusion
That’s it for now — overall the distributed system should be designed as loosely coupled as possible so that even if a failure happens, they are isolated and components can fail safely and independently without cascading it to others. There’s more to it.
This article is just an introduction to system design for failures. In upcoming articles, I’ll be talking about general fault-tolerant strategies like failover mechanism, incremental rollout, graceful degradation, blast radius, circuit breakers, chaos engineering & testing, and much more. Stay tuned!
Copy from https://medium.com/interviewnoodle/system-design-for-failures-series-fd488072fa72